Detectron2 provides several algorithms for instance segmentation, so it was tempting to submit the overlapping datasets to one of those. However, to use one of these algorithms, the dataset format seem to follow the MS-COCO format.
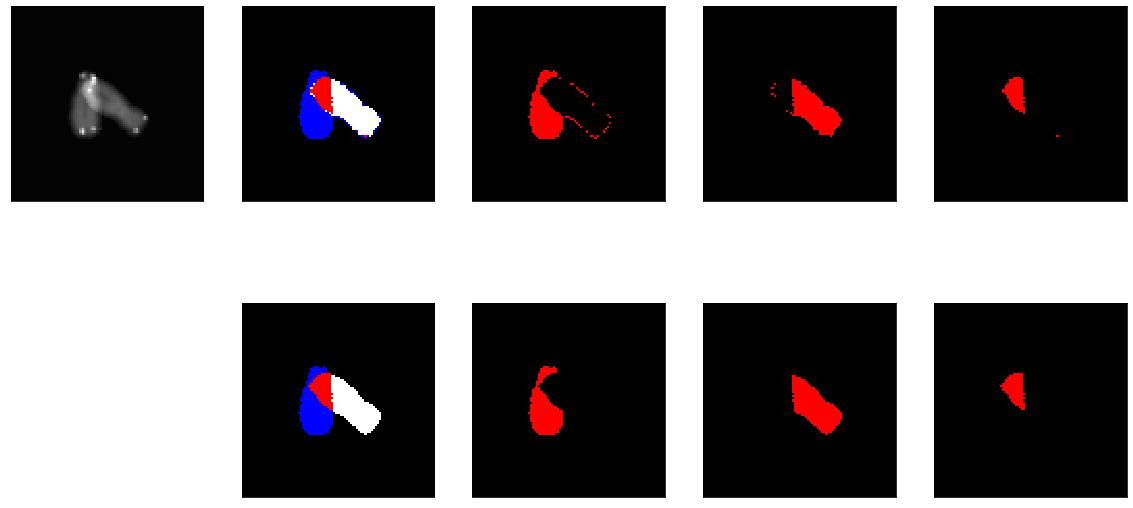
One available dataset consists in 2164 pairs of grayscaled+groundtruth images.To give a try, a minimalist dataset with one image and two instances could be converted to COCO format:
The two instances (right) are obtained from the groundtruth image showing the overlapping chromosomes. The instances are numpy arrays which can be saved as png images. To generate a COCO dataset associated to the gray scaled image (left), the following steps were followed:
generate a python dictionary according to the COCO format specification found in the detectron2 documentation and convert the binary masks to their bounding boxes and compressed rle using pycocotools.
Save the dictionary as a json file
Load the json file with pycocotools (or detectron2) in order to visualize if possible the instances overlaying the gray scaled image.
Unfortunately, the dataset is not a legit COCO dataset as the dataset registration fails. Hope to get some help on Pytorch forum or from stackoverflow.
The image bellow was obtain after sequential hybridization of telomeric PNA probe (FITC:green) followed by hybridization of Alu-PCR product (Rhodamin: Red):
Pairs of chromosomes are ordered by columns from HSA 1 (left) to XY (right) . Metaphases are ordered by row.
Image acquisition was performed with a low resolution 8bits camera mounted on a Leica DMRB fluorescence microscope (100x). Raw images were transferred from a Unix Cytovision station with 3 inch 1/2 floppy disk to a power Macintosh 9500.
Example of a metaphase after alignment of Alu image on DAPI / telomeres images:
Alu images were aligned on DAPI by hand using Photoshop 3 (Here no background correction, nor contrast enhancement)
Whole chromosome painting was also performed sequentially, simultaneously on HSA-13 and HSA-6 and HSA-X:
Karyotyping:
Combining R bands (Alu), G bands (DAPI) and chromosomal painting allows to classify chromosomes in a karyogram:
Left:R Bands (Alu sequences). Right: G bands (Inverse DAPI+DoG filter).
Detectron 2 provides numerous models for semantic/instance segmentation. Contrary to tensorflow 2, the couple pytorch1.3/detectron doesn't seem to require an avx capable CPU. However, detectron 2 works on datasets build according to the COCO format.
Start to think about how to convert the different overlapping chromosomes datasets into a coco dataset:
From version 1.7, tensorflow binary available from anaconda repository, is build with AVX support. To run tensorflow on old cpu missing AVX instructions set, such Xeon E5520, tensorflow must be build from source.
Tensorflow can be build on ubuntu 18.04. Here tensorflow 1.10 will be build for ubuntu 16.04 with CUDA 9.2/cuDNN 7.14 support. Building tensorflow from source relies on the installation of several softwares. Once installed, one can try to run the configure script:
./configure
After some trials, the following configuration seems to succeed for building with CUDA support. From a terminal launch the configure script (here in a virtual environment):
$ ./configure WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown". You have bazel 0.15.0 installed. Please specify the location of python. [Default is /home/jeanpat/anaconda3/envs/DeepFish/bin/python]:
Found possible Python library paths: /home/jeanpat/anaconda3/envs/DeepFish/lib/python3.6/site-packages Please input the desired Python library path to use. Default is [/home/jeanpat/anaconda3/envs/DeepFish/lib/python3.6/site-packages]
Do you wish to build TensorFlow with jemalloc as malloc support? [Y/n]: y jemalloc as malloc support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Google Cloud Platform support? [Y/n]: n No Google Cloud Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Hadoop File System support? [Y/n]: n No Hadoop File System support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Amazon AWS Platform support? [Y/n]: n No Amazon AWS Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Apache Kafka Platform support? [Y/n]: n No Apache Kafka Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with XLA JIT support? [y/N]: y XLA JIT support will be enabled for TensorFlow.
Do you wish to build TensorFlow with GDR support? [y/N]: y GDR support will be enabled for TensorFlow.
Do you wish to build TensorFlow with VERBS support? [y/N]: y VERBS support will be enabled for TensorFlow.
Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: n No OpenCL SYCL support will be enabled for TensorFlow.
Do you wish to build TensorFlow with CUDA support? [y/N]: y CUDA support will be enabled for TensorFlow.
Please specify the CUDA SDK version you want to use. [Leave empty to default to CUDA 9.0]: 9.2
Please specify the location where CUDA 9.2 toolkit is installed. Refer to README.md for more details. [Default is /usr/local/cuda]:
Please specify the cuDNN version you want to use. [Leave empty to default to cuDNN 7.0]: 7.14
Please specify the location where cuDNN 7 library is installed. Refer to README.md for more details. [Default is /usr/local/cuda]:
Do you wish to build TensorFlow with TensorRT support? [y/N]: y TensorRT support will be enabled for TensorFlow.
Please specify the location where TensorRT is installed. [Default is /usr/lib/x86_64-linux-gnu]:
Please specify the NCCL version you want to use. If NCCL 2.2 is not installed, then you can use version 1.3 that can be fetched automatically but it may have worse performance with multiple GPUs. [Default is 2.2]: 1.3.5
Please specify a list of comma-separated Cuda compute capabilities you want to build with. You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus. Please note that each additional compute capability significantly increases your build time and binary size. [Default is: 5.2]:
Do you want to use clang as CUDA compiler? [y/N]: n nvcc will be used as CUDA compiler.
Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]:
Do you wish to build TensorFlow with MPI support? [y/N]: n No MPI support will be enabled for TensorFlow.
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]:
Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n Not configuring the WORKSPACE for Android builds.
Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See tools/bazel.rc for more details. --config=mkl # Build with MKL support. --config=monolithic # Config for mostly static monolithic build. Configuration finished
Building with bazel failed:
According to documentation, the building step was started by typing in a terminal:
Unfortunately, after some hours, the build failed with the error: ./tensorflow/core/util/tensor_format.h:420:3: note: in expansion of macro 'CHECK' CHECK(index >= 0 && index < dimension_attributes.size()) ^ ./tensorflow/core/util/tensor_format.h: In instantiation of 'T tensorflow::GetFilterDim(tensorflow::gtl::ArraySlice<T>, tensorflow::FilterTensorFormat, char) [with T = long long int]': ./tensorflow/core/util/tensor_format.h:461:54: required from here ./tensorflow/core/util/tensor_format.h:435:29: warning: comparison between signed and unsigned integer expressions [-Wsign-compare] CHECK(index >= 0 && index < dimension_attribute.size()) ^ ./tensorflow/core/platform/macros.h:87:47: note: in definition of macro 'TF_PREDICT_FALSE' #define TF_PREDICT_FALSE(x) (__builtin_expect(x, 0)) ^ ./tensorflow/core/util/tensor_format.h:435:3: note: in expansion of macro 'CHECK' CHECK(index >= 0 && index < dimension_attribute.size()) ^ ERROR: /home/jeanpat/Developpement/Arch-TensorFlow/tensorflow/tensorflow/BUILD:576:1: Executing genrule //tensorflow:tensorflow_python_api_gen failed (Aborted): bash failed: error executing command /bin/bash -c ... (remaining 1 argument(s) skipped) 2018-08-22 21:44:49.248926: F tensorflow/core/framework/allocator_registry.cc:52] New registration for AllocatorFactory with name=BFCRdmaAllocator priority=101 at location tensorflow/contrib/gdr/gdr_memory_manager.cc:204 conflicts with previous registration at location tensorflow/contrib/verbs/rdma_mgr.cc:277 /bin/bash: line 1: 17921 Aborted (core dumped) bazel-out/host/bin/tensorflow/create_tensorflow.python_api --root_init_template=tensorflow/api_template.__init__.py --apidir=bazel-out/host/genfiles/tensorflow --apiname=tensorflow --apiversion=1 --package=tensorflow.python --output_package=tensorflow bazel-out/host/genfiles/tensorflow/__init__.py bazel-out/host/genfiles/tensorflow/app/__init__.py bazel-out/host/genfiles/tensorflow/bitwise/__init__.py bazel-out/host/genfiles/tensorflow/compat/__init__.py bazel-out/host/genfiles/tensorflow/data/__init__.py bazel-out/host/genfiles/tensorflow/debugging/__init__.py bazel-out/host/genfiles/tensorflow/distributions/__init__.py bazel-out/host/genfiles/tensorflow/dtypes/__init__.py bazel-out/host/genfiles/tensorflow/errors/__init__.py bazel-out/host/genfiles/tensorflow/feature_column/__init__.py bazel-out/host/genfiles/tensorflow/gfile/__init__.py bazel-out/host/genfiles/tensorflow/graph_util/__init__.py bazel-out/host/genfiles/tensorflow/image/__init__.py bazel-out/host/genfiles/tensorflow/io/__init__.py bazel-out/host/genfiles/tensorflow/initializers/__init__.py bazel-out/host/genfiles/tensorflow/keras/__init__.py bazel-out/host/genfiles/tensorflow/keras/activations/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/densenet/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/inception_resnet_v2/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/inception_v3/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/mobilenet/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/nasnet/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/resnet50/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/vgg16/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/vgg19/__init__.py bazel-out/host/genfiles/tensorflow/keras/applications/xception/__init__.py bazel-out/host/genfiles/tensorflow/keras/backend/__init__.py bazel-out/host/genfiles/tensorflow/keras/callbacks/__init__.py bazel-out/host/genfiles/tensorflow/keras/constraints/__init__.py bazel-out/host/genfiles/tensorflow/keras/datasets/__init__.py bazel-out/host/genfiles/tensorflow/keras/datasets/boston_housing/__init__.py bazel-out/host/genfiles/tensorflow/keras/datasets/cifar10/__init__.py bazel-out/host/genfiles/tensorflow/keras/datasets/cifar100/__init__.py bazel-out/host/genfiles/tensorflow/keras/datasets/fashion_mnist/__init__.py bazel-out/host/genfiles/tensorflow/keras/datasets/imdb/__init__.py bazel-out/host/genfiles/tensorflow/keras/datasets/mnist/__init__.py bazel-out/host/genfiles/tensorflow/keras/datasets/reuters/__init__.py bazel-out/host/genfiles/tensorflow/keras/estimator/__init__.py bazel-out/host/genfiles/tensorflow/keras/initializers/__init__.py bazel-out/host/genfiles/tensorflow/keras/layers/__init__.py bazel-out/host/genfiles/tensorflow/keras/losses/__init__.py bazel-out/host/genfiles/tensorflow/keras/metrics/__init__.py bazel-out/host/genfiles/tensorflow/keras/models/__init__.py bazel-out/host/genfiles/tensorflow/keras/optimizers/__init__.py bazel-out/host/genfiles/tensorflow/keras/preprocessing/__init__.py bazel-out/host/genfiles/tensorflow/keras/preprocessing/image/__init__.py bazel-out/host/genfiles/tensorflow/keras/preprocessing/sequence/__init__.py bazel-out/host/genfiles/tensorflow/keras/preprocessing/text/__init__.py bazel-out/host/genfiles/tensorflow/keras/regularizers/__init__.py bazel-out/host/genfiles/tensorflow/keras/utils/__init__.py bazel-out/host/genfiles/tensorflow/keras/wrappers/__init__.py bazel-out/host/genfiles/tensorflow/keras/wrappers/scikit_learn/__init__.py bazel-out/host/genfiles/tensorflow/layers/__init__.py bazel-out/host/genfiles/tensorflow/linalg/__init__.py bazel-out/host/genfiles/tensorflow/logging/__init__.py bazel-out/host/genfiles/tensorflow/losses/__init__.py bazel-out/host/genfiles/tensorflow/manip/__init__.py bazel-out/host/genfiles/tensorflow/math/__init__.py bazel-out/host/genfiles/tensorflow/metrics/__init__.py bazel-out/host/genfiles/tensorflow/nn/__init__.py bazel-out/host/genfiles/tensorflow/nn/rnn_cell/__init__.py bazel-out/host/genfiles/tensorflow/profiler/__init__.py bazel-out/host/genfiles/tensorflow/python_io/__init__.py bazel-out/host/genfiles/tensorflow/quantization/__init__.py bazel-out/host/genfiles/tensorflow/resource_loader/__init__.py bazel-out/host/genfiles/tensorflow/strings/__init__.py bazel-out/host/genfiles/tensorflow/saved_model/__init__.py bazel-out/host/genfiles/tensorflow/saved_model/builder/__init__.py bazel-out/host/genfiles/tensorflow/saved_model/constants/__init__.py bazel-out/host/genfiles/tensorflow/saved_model/loader/__init__.py bazel-out/host/genfiles/tensorflow/saved_model/main_op/__init__.py bazel-out/host/genfiles/tensorflow/saved_model/signature_constants/__init__.py bazel-out/host/genfiles/tensorflow/saved_model/signature_def_utils/__init__.py bazel-out/host/genfiles/tensorflow/saved_model/tag_constants/__init__.py bazel-out/host/genfiles/tensorflow/saved_model/utils/__init__.py bazel-out/host/genfiles/tensorflow/sets/__init__.py bazel-out/host/genfiles/tensorflow/sparse/__init__.py bazel-out/host/genfiles/tensorflow/spectral/__init__.py bazel-out/host/genfiles/tensorflow/summary/__init__.py bazel-out/host/genfiles/tensorflow/sysconfig/__init__.py bazel-out/host/genfiles/tensorflow/test/__init__.py bazel-out/host/genfiles/tensorflow/train/__init__.py bazel-out/host/genfiles/tensorflow/train/queue_runner/__init__.py bazel-out/host/genfiles/tensorflow/user_ops/__init__.py Target //tensorflow/tools/pip_package:build_pip_package failed to build Use --verbose_failures to see the command lines of failed build steps. INFO: Elapsed time: 7962.287s, Critical Path: 283.59s INFO: 7346 processes: 7346 local. FAILED: Build did NOT complete successfully
What to do? Trying to rebuild with a minimalist configuration (keeping cuda acceleration)
./configure again
This time with less optimizations (keep XLA and CUDA):
$ ./configure WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown". You have bazel 0.15.0 installed. Please specify the location of python. [Default is /home/jeanpat/anaconda3/envs/DeepFish/bin/python]:
Found possible Python library paths: /home/jeanpat/anaconda3/envs/DeepFish/lib/python3.6/site-packages Please
input the desired Python library path to use. Default is
[/home/jeanpat/anaconda3/envs/DeepFish/lib/python3.6/site-packages]
Do you wish to build TensorFlow with jemalloc as malloc support? [Y/n]: y jemalloc as malloc support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Google Cloud Platform support? [Y/n]: n No Google Cloud Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Hadoop File System support? [Y/n]: n No Hadoop File System support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Amazon AWS Platform support? [Y/n]: n No Amazon AWS Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Apache Kafka Platform support? [Y/n]: n No Apache Kafka Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with XLA JIT support? [y/N]: y XLA JIT support will be enabled for TensorFlow.
Do you wish to build TensorFlow with GDR support? [y/N]: n GDR support will be enabled for TensorFlow.
Do you wish to build TensorFlow with VERBS support? [y/N]: n VERBS support will be enabled for TensorFlow.
Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: n No OpenCL SYCL support will be enabled for TensorFlow.
Do you wish to build TensorFlow with CUDA support? [y/N]: y CUDA support will be enabled for TensorFlow.
Please specify the CUDA SDK version you want to use. [Leave empty to default to CUDA 9.0]: 9.2
Please
specify the location where CUDA 9.2 toolkit is installed. Refer to
README.md for more details. [Default is /usr/local/cuda]:
Please specify the cuDNN version you want to use. [Leave empty to default to cuDNN 7.0]: 7.14
Please
specify the location where cuDNN 7 library is installed. Refer to
README.md for more details. [Default is /usr/local/cuda]:
Do you wish to build TensorFlow with TensorRT support? [y/N]: n TensorRT support will be enabled for TensorFlow.
Please specify the location where TensorRT is installed. [Default is /usr/lib/x86_64-linux-gnu]:
Please
specify the NCCL version you want to use. If NCCL 2.2 is not installed,
then you can use version 1.3 that can be fetched automatically but it
may have worse performance with multiple GPUs. [Default is 2.2]: 1.3.5
Please specify a list of comma-separated Cuda compute capabilities you want to build with. You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus. Please note that each additional compute capability significantly increases your build time and binary size. [Default is: 5.2]:
Do you want to use clang as CUDA compiler? [y/N]: n nvcc will be used as CUDA compiler.
Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]:
Do you wish to build TensorFlow with MPI support? [y/N]: n No MPI support will be enabled for TensorFlow.
Please
specify optimization flags to use during compilation when bazel option
"--config=opt" is specified [Default is -march=native]:
Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n Not configuring the WORKSPACE for Android builds.
Preconfigured
Bazel build configs. You can use any of the below by adding
"--config=<>" to your build command. See tools/bazel.rc for more
details. --config=mkl # Build with MKL support. --config=monolithic # Config for mostly static monolithic build. Configuration finished
From a terminal, call an ipython console (here in DeepFish virtualenv) and type:
(DeepFish) jeanpat@Dell-T5500:~/Developpement$ ipython Python 3.6.5 | packaged by conda-forge | (default, Apr 6 2018, 13:39:56) Type 'copyright', 'credits' or 'license' for more information IPython 6.5.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import tensorflow as tf
In [2]: tf.__version__ Out[2]: '1.10.0' In [3]: hello = tf.constant('Hello, Tensorflow!')
In [4]: sess = tf.Session() 2018-08-23 15:37:45.588128: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:964] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2018-08-23 15:37:45.588830: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Found device 0 with properties: name: GeForce GTX 960 major: 5 minor: 2 memoryClockRate(GHz): 1.253 pciBusID: 0000:03:00.0 totalMemory: 3.95GiB freeMemory: 3.68GiB 2018-08-23 15:37:45.588860: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1485] Adding visible gpu devices: 0 2018-08-23 15:37:45.997955: I tensorflow/core/common_runtime/gpu/gpu_device.cc:966] Device interconnect StreamExecutor with strength 1 edge matrix: 2018-08-23 15:37:45.998007: I tensorflow/core/common_runtime/gpu/gpu_device.cc:972] 0 2018-08-23 15:37:45.998035: I tensorflow/core/common_runtime/gpu/gpu_device.cc:985] 0: N 2018-08-23 15:37:45.998306: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1098] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 3402 MB memory) -> physical GPU (device: 0, name: GeForce GTX 960, pci bus id: 0000:03:00.0, compute capability: 5.2)
In [5]: print(sess.run(hello)) b'Hello, Tensorflow!'
Here, the telomere length of several chromosomes is modeled numerically with segregation of chromosomes in daughter cells. The model takes the 5' degradation of the CCCTAA strand into account. The aim of the simulation is to compare the distributions with QFISH data. The model shows that the telomeres length at pter and qter are correlated for a given homologous chromosome. It can be used to derive statistical tests to detect telomere length difference between homologous chromosomes.
Some unit tests can be run, a jupyter notebook is available (see the link to gist), they yield:
Model structure:
The model consists in a classCell which have a Genome, which have chromosomes, which have two complementary single strands DNA (Watson/Crick). Each strand has two telomeres.
A single strand object can be instantiated as follow:
A chromosome object is instantiated with two complementary Watson/Crick strands:
For example, two chromosomes, rosalind and franklin can be instantiated as follow:
After a round of DNA replication, 5' CCCTAA motifs are incompletely
replicated and TTAGGG 3' can be randomly degraded, leading to shorter
telomeres on metaphasic chromosomes on both chromatids at pter and qter. Iin the G2 state a chromosome has two chromatids, the length of a
telomere on a given arm (pter ou qter) is given by two values:
The ros chromosome object keeps its signature before and after the mitosis:
Signature of the ros chromosome in the G2 state before mitosis
Definition of a Genome object:
It is convenient to define a genome object, it is instantiated for example with two chromosomes (2N=2):
The genome state (G1/G2), the chromosomes of the genome can be accessed to read the telomere length (CCCTAA or TTAGGG motifs), the length difference between homologous telomeres:
Cell object has a genome:
Unit test results for Cell object
Once a single genome object is instantiated, a single cell object can be instantiated. Let's build a cell with 2N=10:
The length of the telomeres (bp) in that single cell can be read from a pandas dataframe:
Let's allow 10 synchronous cellular divisions from 1 cell to 1024 cells. Then as for fibroblasts cultures, let's make passages, that is one allows only half randomly chosen cells to divide once:
Results
The envelope of the telomere length distribution at a single telomere after 14 divisions (10 divisions + 4 passages) seems to be gaussian:
Correlation between the length at pter and qter on the same homolog
The length of the telomeres (pter, qter) of the same homologous chromosome (the maternal one for example) are correlated:
It is possible to plot the telomeres length of two homologous chromosomes:
The length of the telomeres belonging to different homologous are not correlated.
Let's plot the length of the telomere from the paternal chromosome 1 at qter as a function of the length of the telomere at 1qter on the maternal homolog:
Mean telomere length in synchronous dividing cells population:
In telomerase negative cells as modeled here, the telomere length decreases with cells divisions.
The decrease of telomere length depends on the 5' exonuclease
activity. The amount of degraded DNA is modeled here by random variable, X, following a binomial law
(N=400, p=0.4) :
Distribution of X: P(130<X<200)=0.999
to fit the data of Makarov et al. (1997) as follow:
taking the RNA primer deletion (20 bp), the mean length of the 3' s G strand is:
160 +20 bp
As published in 1992, the
standard deviation of the telomere length increase at each cell
division.
So the mean telomere length, , was plotted as a function of the cell divisions after an expansion of ten cellular divisions and four passages.
The mean telomere length decreases by 90 bp/div
and the heterogeneity increases:
At each passage the length of each telomere (column) of each cell (row) of the simulation is copied in a pandas data-frame, for example at passage P4:
Then the mean telomere length in the whole cells population can be calculated:
Using seaborn, the telomere length of some homologs can be compared:
Population of Mixed Cells
Cells from different passages can be mixed, for example in equal proportions. The correlation between pter and qter of a given homolog should start to vanish:
Senescence in-silico:
Short telomeres trigger an irreversible transition to state of the cell cycle (senescence). Let's take a cells population, make successive passages. Initial cells population is expended from one cell (telomerase off) after eight divisions. The genome of the initial cell is instantiated with 2N=4 and with the length of the shortest telomere set to 2000 bp.
At each passage, it's possible to count the cells in the state or to calculate the confluence of the cells population. The threshold telomere length triggering the G0 state is set arbitrarily to 200 bp. The initial population is passed 20 times:
The confluence is calculated as the number of cells at a given passage by the initial number of cells. With the shortest initial telomere length set to 2000 bp, the confluence reach 50% after 18 doublings:
Senescence in silico: confluence (100 N cell/ N initial cells) decreases with cells divisions










































{kind=link}